Beyond Static Accuracy: Introducing the Policy Steerability Benchmark
A new way to measure how likely a model is to accurately follow your rules

TL;DR: Last week we released CoPE-B — our next-generation policy-adaptive content classifier model. The standard benchmarks that we published showed some F1 accuracy gains over CoPE-A, but didn't reflect the real step up in CoPE-B's policy-following capability. So today we are sharing a brand new benchmark that better captures how likely a model is to accurately follow any given policy-- we call it policy steerability. This new metric clearly shows how both fixed taxonomy models and most open weight models struggle with policy steerability. CoPE-B, it turns out, is the only self-deployable model that is both efficient and steerable, which helps to explain why we believe it is the best model in the world for at-scale content classification.
A gap that didn't show up on the dashboard
When we shipped CoPE-B-A4B and its multimodal sibling CoPE-B-A4B-MM last week, the headline accuracy improvements were real but modest: an unweighted-mean F1 of 0.81 (and 0.82 for the multimodal variant) on our held-out test set, versus 0.80 for CoPE-A-9B.
But the F1 number missed something that we experienced subjectively. Every time we picked up the new model, it felt dramatically more capable. Relative to CoPE-A, when revising a policy, CoPE-B would much more faithfully update its behavior. For example, when a policy had a permissive carve-out — like "direct swearing at adults is allowed" — CoPE-A might miss that detail. CoPE-B would honor it.
This is the disconnect that motivated the work below. F1 against a static test set typically measures whether the model agrees with one ground-truth labeler on one specific policy. It doesn't measure what we actually care about: whether the model adapts to the policy you wrote. For that, we had to build a new benchmark.
Most content safety benchmarks ask the wrong question
They ask: does this model correctly identify hate speech? Or: how well does it detect sexual content? These are reasonable questions. But they assume that "hate speech" and "sexual content" are fixed categories — that what counts as a violation is universally agreed upon, and the model's job is to apply that judgment consistently.
In the real world, that's rarely how it works.
A gaming platform's definition of harassment is different from a children's app's. A news organization needs to allow graphic content that a social network would remove. A medical community needs to discuss self-harm in ways that would be inappropriate on a general platform. Every platform team writes their own policies — and then spends years fighting to get their systems to actually follow them.
That gap is what policy steerability measures.
What policy steerability measures
Our policy steerability benchmark starts from a simple idea: take the same piece of content and give the model two different policies — one that clearly should flag it, one that clearly should permit it. A steerable model follows both. An unsteerable model gives the same answer regardless of which policy you gave it.
More precisely: for each contrastive pair, we present a model with:
policy_pos— a policy under which this content should be flagged (ground truth: 1)policy_neg— a policy under which this content should be allowed (ground truth: 0)
The model's policy steerability score is the fraction of pairs where it gets both right simultaneously. Partial credit is not awarded. A model that flags everything scores 0 — it gets the pos cases right but fails every neg case. A model that allows everything also scores 0.
This makes policy steerability a demanding joint constraint: the model must understand why a policy applies, not just pattern-match to the content.
The hardest part is the negative. Getting a model to flag content is easy — most safety models are conservatively tuned to err on that side. The hard part is getting a model to allow content when the policy says to. That requires genuine policy interpretation, not reflexive caution. And it's where almost every existing open model fails.
Why this benchmark has been hard to build
Until now, policy steerability as a concept has been largely missing from the literature. Most benchmarks test against fixed harm taxonomies: a model either knows the taxonomy or it doesn't. Even the most thoughtful evaluations focus primarily on F1 accuracy against a labeled test set, which tests consistency but not adaptability.
The core challenge is that building a policy steerability benchmark requires contrastive policy pairs, not just labeled content. You need pairs of policies that produce genuinely opposite ground-truth labels for the same content — which means having enough policy and content diversity in your training data to construct them naturally.
We were able to build ours from the held-out portion of our CoPE training data. Because CoPE is trained on diverse policy/content pairs across many harm categories and policy variations, we had the raw material to construct thousands of such contrastive pairs covering topics like hate speech, self-harm, harassment, sexual content, and drugs. Neither the policies nor the content in these pairs were ever used in training any model evaluated here. For full methodological detail, see our arXiv paper (arXiv:2512.18027).
Results
We evaluated 28 model configurations across five tiers on over a thousand contrastive pairs. A quick note on interpretation: these results should be read directionally. We ran each model in a zero-shot setting with a consistent prompt format, so models not designed for BYOP (Bring Your Own Policy) labeling are disadvantaged here — which is partly the point.
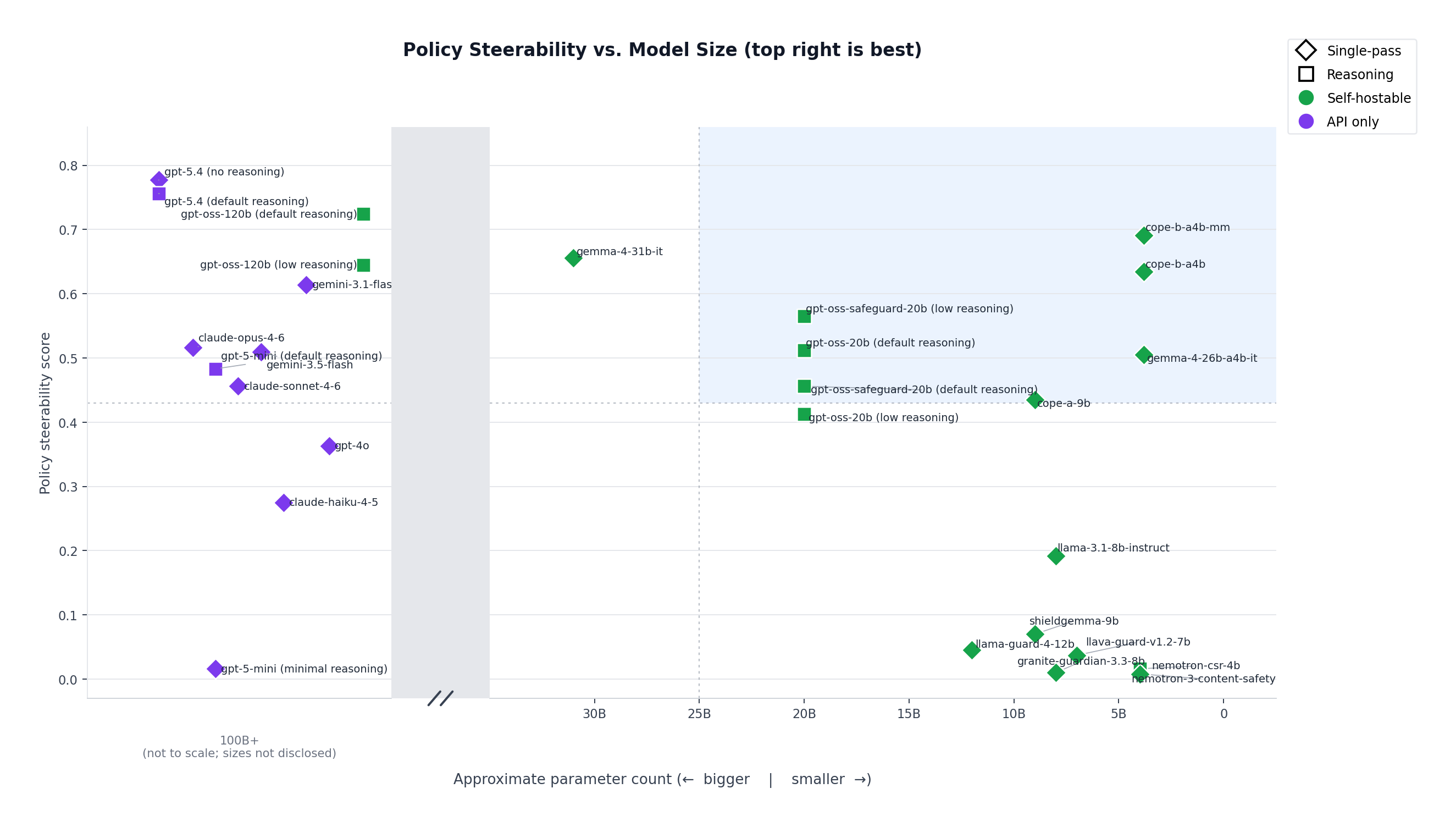
The leaderboard
| Model | Steerability | Pos acc | Neg acc | Small | Self-hostable | Single-pass | Flexible policy |
|---|---|---|---|---|---|---|---|
| gpt-5.4 (no reasoning) | 0.777 | 0.902 | 0.869 | ✓ | ✓ | ||
| gpt-5.4 (default reasoning) | 0.756 | 0.912 | 0.838 | ✓ | |||
| gpt-oss-120b (default reasoning) | 0.724 | 0.915 | 0.800 | ✓ | ✓ | ||
| cope-b-a4b-mm | 0.691 | 0.785 | 0.895 | ✓ | ✓ | ✓ | ✓ |
| gemma-4-31b-it | 0.656 | 0.775 | 0.875 | ✓ | ✓ | ✓ | |
| gpt-oss-120b (low reasoning) | 0.645 | 0.921 | 0.708 | ✓ | ✓ | ||
| cope-b-a4b | 0.634 | 0.849 | 0.777 | ✓ | ✓ | ✓ | ✓ |
| gemini-3.1-flash-lite | 0.614 | 0.784 | 0.818 | ? | ✓ | ✓ | |
| gpt-oss-safeguard-20b (low reasoning) | 0.565 | 0.897 | 0.662 | ✓ | ✓ | ✓ | |
| claude-opus-4-6 | 0.516 | 0.971 | 0.538 | ✓ | ✓ | ||
| gpt-oss-20b (default reasoning) | 0.512 | 0.854 | 0.614 | ✓ | ✓ | ✓ | |
| gemini-3.5-flash | 0.509 | 0.850 | 0.626 | ✓ | ✓ | ||
| gemma-4-26b-a4b-it | 0.505 | 0.754 | 0.740 | ✓ | ✓ | ✓ | ✓ |
| gpt-5-mini (default reasoning) | 0.483 | 0.980 | 0.498 | ? | ✓ | ||
| claude-sonnet-4-6 | 0.456 | 0.877 | 0.530 | ✓ | ✓ | ||
| gpt-oss-safeguard-20b (default reasoning) | 0.456 | 0.799 | 0.610 | ✓ | ✓ | ✓ | |
| cope-a-9b | 0.435 | 0.928 | 0.504 | ✓ | ✓ | ✓ | ✓ |
| gpt-oss-20b (low reasoning) | 0.413 | 0.870 | 0.521 | ✓ | ✓ | ✓ | |
| gpt-4o | 0.363 | 0.894 | 0.465 | ✓ | ✓ | ||
| claude-haiku-4-5 | 0.275 | 0.645 | 0.470 | ? | ✓ | ✓ | |
| llama-3.1-8b-instruct | 0.192 | 0.711 | 0.301 | ✓ | ✓ | ✓ | ✓ |
| shieldgemma-9b | 0.070 | 0.927 | 0.140 | ✓ | ✓ | ✓ | |
| llama-guard-4-12b | 0.045 | 0.759 | 0.275 | ✓ | ✓ | ✓ | |
| llava-guard-v1.2-7b | 0.037 | 0.876 | 0.147 | ✓ | ✓ | ✓ | |
| nemotron-content-safety-reasoning-4b | 0.016 | 0.994 | 0.019 | ✓ | ✓ | ||
| gpt-5-mini (minimal reasoning) | 0.016 | 0.998 | 0.017 | ? | ✓ | ✓ | |
| granite-guardian-3.3-8b | 0.010 | 0.945 | 0.053 | ✓ | ✓ | ✓ | |
| nemotron-3-content-safety | 0.008 | 0.919 | 0.073 | ✓ | ✓ | ✓ |
*Steerability = fraction of contrastive pairs where the model correctly follows both policies.
*Pos acc / Neg acc = accuracy on positive / negative policy items.
*Small = less than 25B parameters
*Self-hostable = model weights are available to download.
*Single-pass = produces classification in one forward pass with no internal reasoning chain.
*Flexible policy = accepts arbitrary user-supplied policies rather than classifying against a built-in fixed taxonomy.
Speed vs. Steerability vs. Self-hosting: Pick all 3?
A useful production classifier needs three properties at once:
- Steerable — it actually follows the policy text you wrote, including permissive policies that say "don't flag."
- Self-hostable — you can access model weights in order to avoid per-call API costs or vendor lock-in.
- Single-pass — it classifies in one forward pass, not by emitting hundreds of intermediate reasoning tokens that drive latency and cost up at scale.
The results above make clear that almost no model checks all three boxes. The market instead splits into archetypes that each give up at least one attribute:
- Frontier closed-API models (GPT-5.4, Claude-Opus, Gemini Flash) sometimes achieve high steerability, but they're closed APIs. GPT-5.4 leads at 0.78 / 0.76, but you pay per call, ship every input out of your data plane, and have no recourse when a model deprecates. Claude-Opus-4.6 at 0.52 shows how heavily safety-tuning can bias against permissive policies — its NegAcc of 0.54 means it fires ~47% of the time when the policy says don't.
- Open-weight reasoning models (gpt-oss-120b, gpt-oss-20b, Nemotron Content Safety Reasoning) achieve steerability by emitting a chain-of-thought before answering. At default reasoning, gpt-oss-120b reaches 0.72 — third overall and the strongest open-weight model in the table. But drop to
reasoning_effort="low"to cut latency and gpt-oss-120b plummets to 0.65 (−8 pts). Hundreds of reasoning tokens per classification is a non-starter for high-volume labeling. - Fixed-taxonomy safety classifiers (LlamaGuard, ShieldGemma, LlavaGuard, Granite-Guardian, Nemotron Content Safety) are open and single-pass but were never designed to follow your rules. The whole family clusters below 0.10 — ShieldGemma 0.07, LlamaGuard 0.05, LlavaGuard 0.04, Granite-Guardian 0.01, Nemotron-3 0.01. Well-built for their definitions, but can't easily follow yours.
- General instruction-tuned models (Llama-3.1-8B-Instruct, gpt-4o, Claude-Sonnet/Haiku) are open or fast, sometimes both, but their safety priors seem to fire by default regardless of what the policy says. Llama-3.1-8B at 0.19, Claude-Haiku at 0.28, gpt-4o at 0.36, Claude-Sonnet at 0.46 — high PosAcc paired with low NegAcc across the board. Instruction-tuning alone is apparently not the same as policy-following.
CoPE-B-A4B stands alone as the only model purpose-built for the missing quadrant: frontier-level steerability that you can efficiently self-host. Every model above CoPE-B-A4B-MM on the leaderboard is either closed or reasoning-bound — resulting in far greater cost or latency per call. And every self-hostable, single-pass model below it fails the steerability test outright.
Why this matters for your platform
Zentropi is built on the conviction that when you write a rule, your system should follow it. That's a deceptively hard problem, and the numbers above show just how many models struggle with it.
To a first approximation, a model with a policy steerability score of 0.10 is responsive to your policy changes only 1 in 10 times. This means you write a policy, deploy it, and find the model behaves more or less the same regardless of what you wrote. You iterate on your policy language. But it still doesn't change. You're effectively using a fixed-taxonomy classifier that follows someone else's rules.
By contrast, a model like CoPE-B with a policy steerability score of 0.69 is more likely to follow your rules-- it is ~ 7x better at navigating policy changes. For policies with subtle distinctions, that's the difference between a labeling system you can trust and one you can't actually control.
Open questions
We think policy steerability as a metric deserves more attention from the research community. Some questions we're sitting with:
Is there a ceiling below frontier scale? GPT-5.4 reaches 0.78 with reportedly over a trillion parameters, whereas CoPE-B-A4B-MM gets to 0.69 with 3.8 billion active parameters. Can that 0.09-absolute gap be closed with further training, or does it require a much bigger base or a different architecture altogether?
Does policy steerability generalize across domains? Our benchmark covers many topical areas but is not fully comprehensive. We expect steerability patterns to differ by harm category and cultural context, and we'd like to see more balanced benchmarks built by others.
Why does reasoning sometimes hurt? GPT-5.4 gains 0.02 with reasoning off, whereas gpt-oss-safeguard at low reasoning regresses by 0.11. We suspect models trained to reason their way through ambiguous situations sometimes talk themselves out of correct judgments — but we don't yet have a clean account of when and why.
Evaluating your model
We're happy to run any model on this benchmark. The dataset itself isn't public — we can't release the contrastive pairs without enabling benchmark overfitting — but if you have a model you'd like evaluated, reach out to us at info@zentropi.ai. We'll run it and share the results.