Zentropi Now Labels Videos
Building guardrails for video content just got a lot easier. Today we're launching video classification on Zentropi — a new capability unlocked by our just-released multimodal model CoPE-B-A4B-MM
When we launched image labeling earlier this year, we set out to bring Zentropi's policy-first approach to one more modality at a time. Text first, then images. With CoPE-B-A4B-MM now in production, video joins the club.
This multimodal model is the first member of the CoPE family with native video understanding. That enables Zentropi to now provide full-stack support for creating video classifiers.
Why Video Matters
The fastest-growing surfaces on the internet are video: livestreams, short clips, AI-generated reels, video DMs. Each one is harder to evaluate at scale than text or images.
Traditional approaches force a familiar bad choice — human reviewers who can't keep up with the volume, or off-the-shelf classifiers built around someone else's taxonomy. And as AI video generation hits consumer scale, prompt-side filtering, already brittle for images, falls apart even faster. A prompt that reads as innocent can produce a video you very much don't want on your platform.
Now you can analyze the videos themselves — against your policies, at scale.
How It Works
If you've built text or image labelers with Zentropi, video labeling will feel familiar. Write a policy describing what you want to detect, test it with sample content, and deploy to production. Our automation tools make it easy for even non-policy experts to draft and optimize labeling criteria.
What changes is what you're evaluating. Instead of pixels or messages, you're looking at sequences of imagery — user uploads, livestream frames, AI-generated clips, anything video flowing through your system.
The Model Behind It
Video labeling is powered by CoPE-B-A4B-MM, the multimodal variant of our newly-released CoPE-B model. The same policy-steerable architecture that powers text and image classification now extends natively to video — not as a stitched-together pipeline of specialized models, but as a single model that understands the video modality directly.
CoPE-B-A4B-MM brings a 256k context window, so you can write richer, more detailed policies and the model can apply them across video content up to 60 seconds in length without losing the thread.
Same policy-first approach. Same accuracy targets. Now with video.
This feature is available for subscribers only, who can also download the model weights for self-hosting — enabling video classification entirely within your own infrastructure if that's what your security posture requires.
What You Can Build
Zentropi Video Labelers are a great fit for:
Livestreaming platforms — Evaluate live video against your community guidelines as it streams, instead of waiting for after-the-fact reports.
AI video generation — Detect nudity, violence, or brand-unsafe content in generated videos — not just in the prompts. Add a safety layer after generation but before serving to users.
Social and UGC platforms — Analyze uploaded videos, profile clips, and shared content against your specific policies, instead of accepting another vendor's defaults.
Marketplaces and e-commerce — Screen seller-uploaded product videos for prohibited items, misleading demonstrations, or content that violates your terms.
Brand safety — Verify ad creative, sponsored content, and AI-generated marketing video before it goes live.
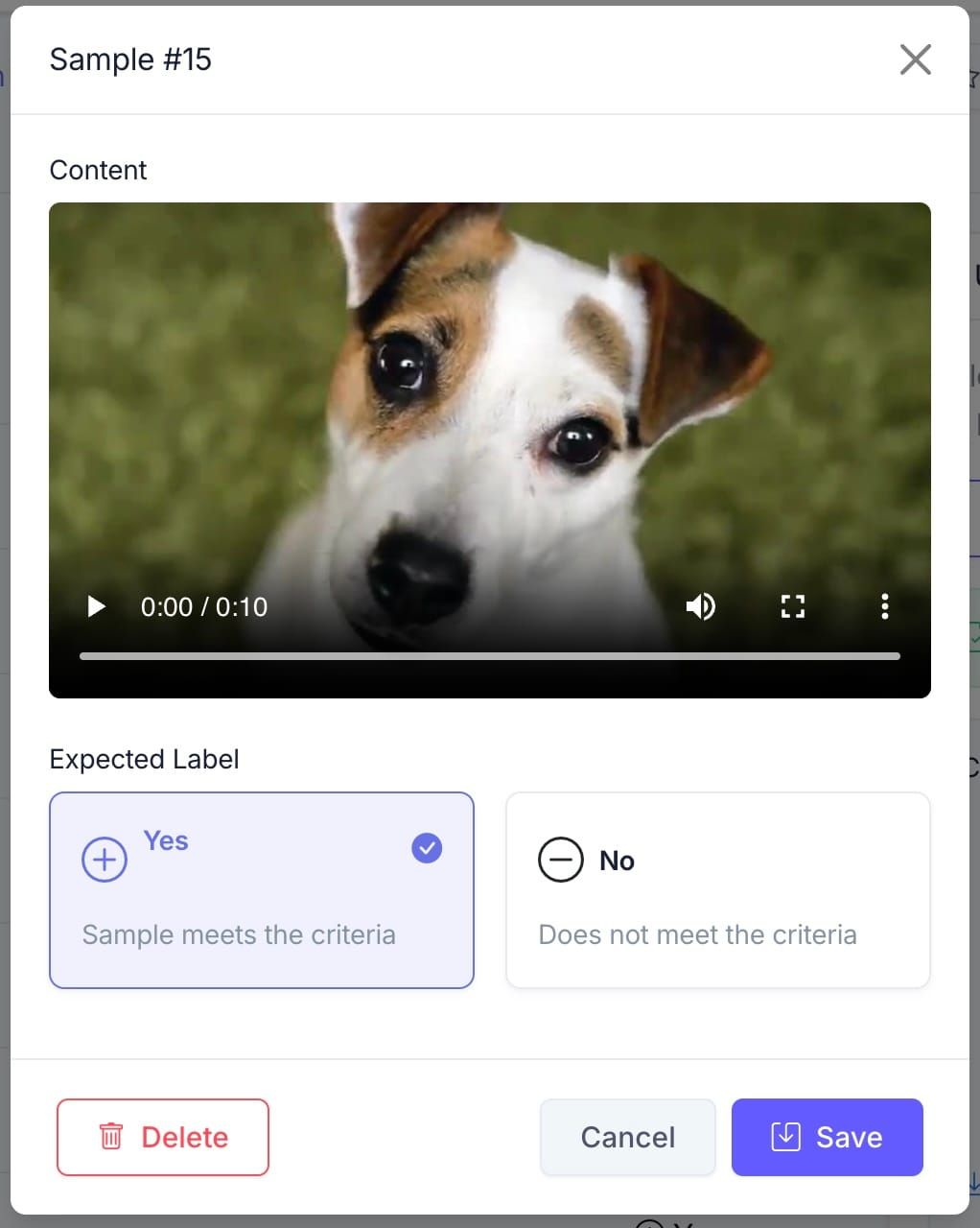
Obligatory Dog Example
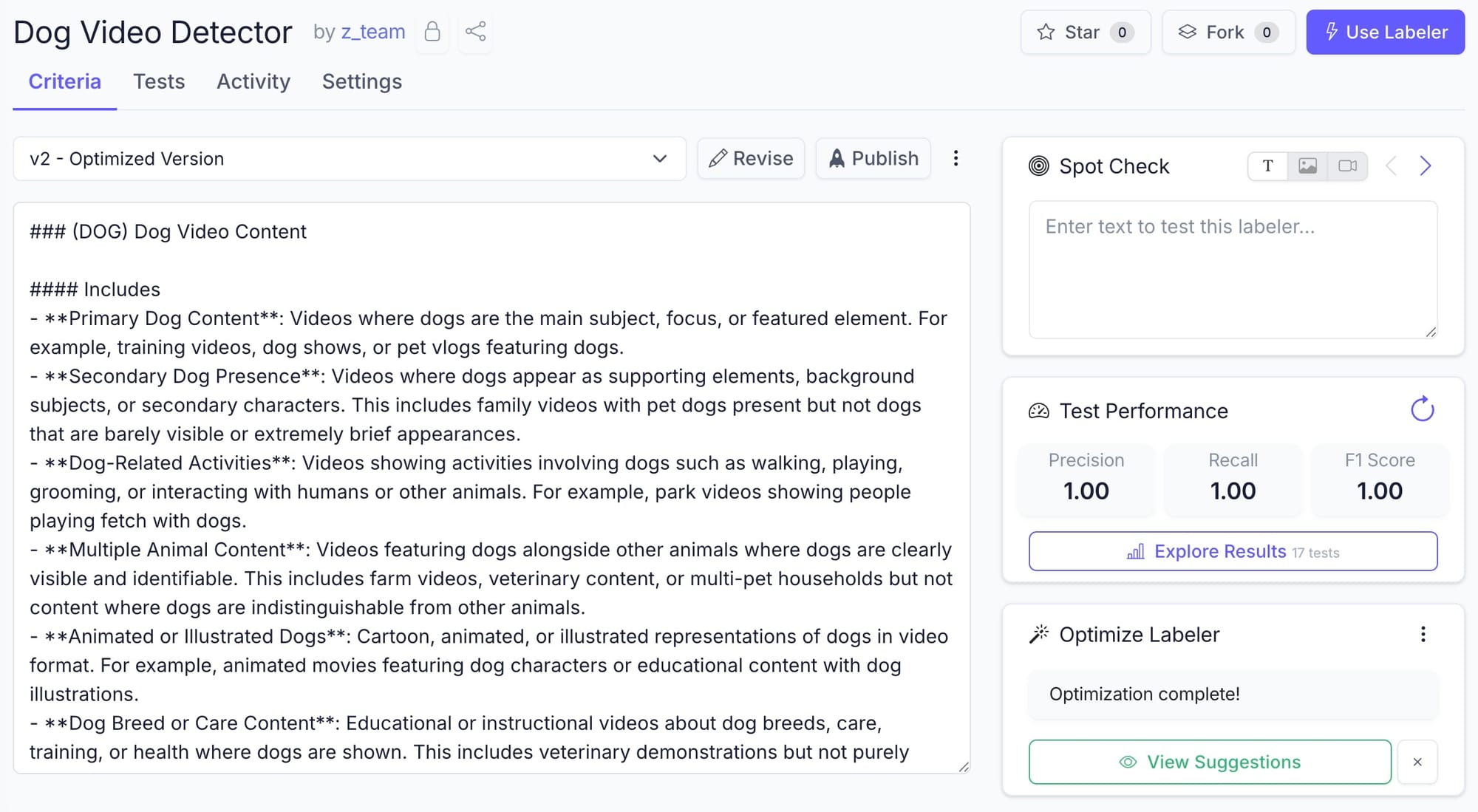
Cats had their turn last time when we introduced image classifiers. This round goes to dogs. We set out to build a labeler that detects videos of dogs doing dog things — tails wagging, chasing tennis balls, sitting on command, the full repertoire.
Then we uploaded a CSV of labeled video clips: dogs (1/yes) and not-dogs (0/no).
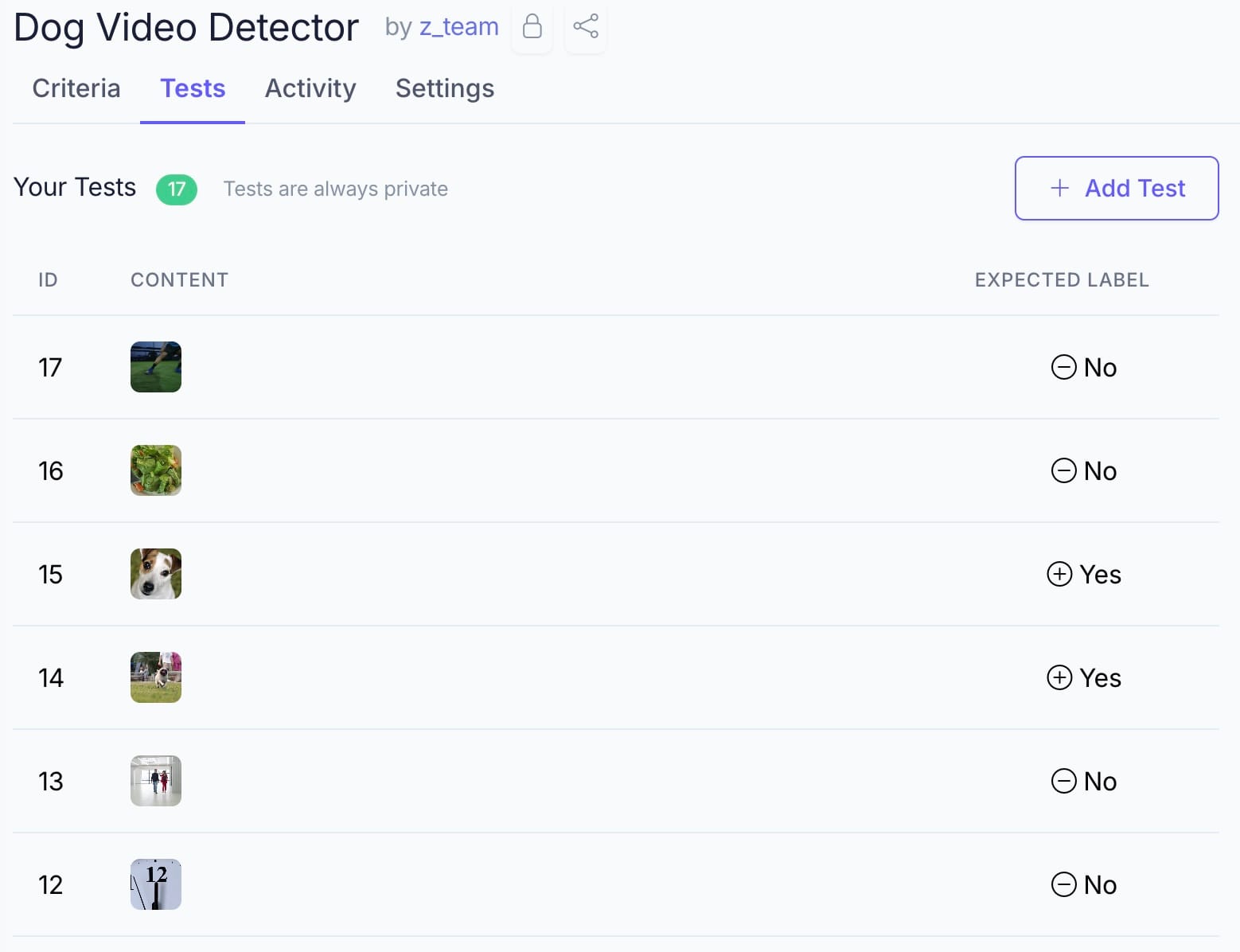
The first pass came back strong — perfect precision and recall across the test set.
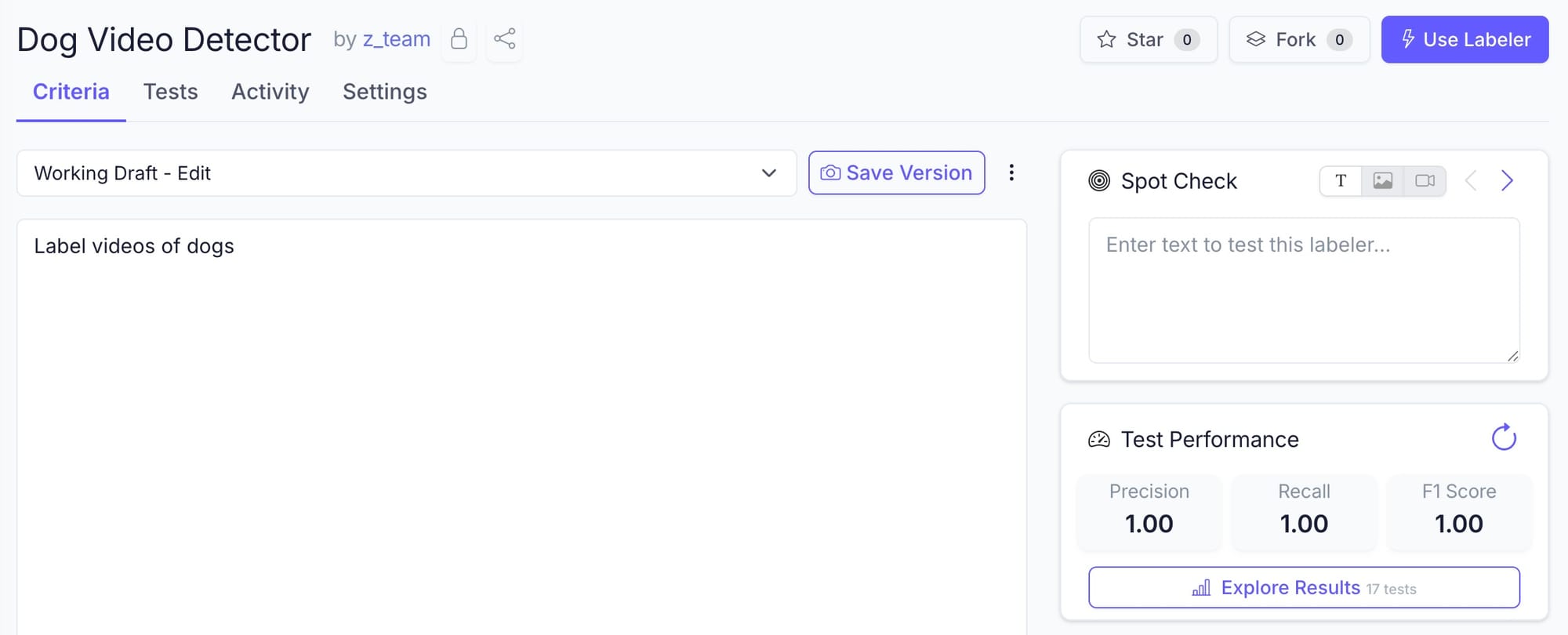
For fun, we ran the optimizer to tighten the criteria around the edge cases that could fool us — cartoons of dogs, coyotes and wolves that look like dogs, and puppies just barely too small to read as dogs.
Then we instantly deployed to the API, ready to integrate into any system.
All told, it took mere minutes to make a custom video labeler that runs extremely fast and at a fraction of the cost of having a frontier model do it. At just 4 billion active parameters, Zentropi-powered video classifers are extremely fast and efficient to operate.
Getting Started
Video labeling is available today for our paid customers. If you're on our Community tier, you can continue building and testing text labelers for free — and upgrade when you're ready to add image or video.
To create your first video labeler:
- Log in to zentropi.ai
- Create a new labeler
- Write your policy in plain English (or have one generated for you)
- Upload test videos and refine until you're confident
- Publish and integrate via our API
If you aren't yet a subscriber but are interested in evaluating this solution or thinking through your video safety strategy, reach out at info@zentropi.ai. We've helped teams across social, generative AI, and brand safety build guardrails that work.